예전에 필자도 설문조사 하였다. 하지만, 설문지 문항에 대한 신뢰도는 조사는 하지 않고, 그냥 평균만 분석해서 보고 한 적이 있었는데, 이번에는 설문문항 신뢰도에 대해 다루어 볼 예정 이다.
 |
| 설문문항 신뢰도 |
R을 다룰 때는 사회 조사 방법론을 다루기 보다는 자재 소요예측이나, 고장 예측 같은 것만 해왔고, 사람의 심리를 척도(리카도 척도)와 해서 알아보는 것은 이번이 처음이다.
원래 네이버 지식In에서 질문은 회귀 모형을 만들어 달라고 하는 이야기인데, 이번에는 설문 문항의 신뢰도 만 보겠다. 실제로 설문 문항의 결과에 따라서 비교모형은 만들수 있는데, 회귀모형은 만들기가 정말 어렵다.
문항의 신뢰도
교육학 및 심리학 등의 여러 분야에서 자주 활용되는 설문지 또는 시험지 문항의 신뢰성은 매우 중요한 문제이다.
신뢰성(reliability)은 안정성(stability), 일관성(consistency), 예측 가능성(predictability) 등과 관련된 개념으서 동일한 사람이 다른 환경에서 똑같은 설문지를 재반복 하거나, 동등한 항목으로 이루어진 서로 다른 설문지를 대상을 측정하는 경우 결과가 비슷하게 나타나야 함을 의미한다.
아래 설문지를 작성 할때, 가장의 충실도라고 하는 정도를 측정 한다고 할때, 다음과 같은 문항
문 당신은 가장으로서 가정에 충실하다고 생각 하십니까?
① 전혀 그렇지 않다. ② 그렇지 않다. ③ 보통이다. ④ 그렇다. ⑤ 매우 그렇다.
를 통하여 측정 한다면, 올바른 측정이 되지 않을 것이다.
추상적인 개념을 측정 하기 위해서는 가장의 충실도와 관련된 문항들을 통해서 객관적으로 측정 할 수 있어 야 한다.
문1. 당신은 휴일에 집안일을 도와줍니까?
문2 . 당신은 자녀들과 대화의 시간을 자주 가집니까?
문3. 자녀 들의 과제를 같이 고민 한 적이 있습니까?
문4. 휴가 때 가족들과 여행을 하십니까?
위와 같은 문제는 가장의 충실도에 대한 문항들을 통해서 우리는 추상적인 개념을 객관적으로 측정 할 수 있다.
내적 일치도 신뢰계수
위에서 $ X_1, X_2, \cdot\cdot\cdot, X_k $ 와 같이 다양한 항목들의 전체를 척도(scale)라고 하며, $Var(∑x_i)$ 는 각 문항들의 합의 분산을 말하며, $∑Var(X_i)$는 각 문항들의 분산의 합을 나타내며, 상관계수가 작다고 하더라도 문항 수가 충분히 커지면 크론바 α 값은 1에 가깝게 된다.
R 분석의 예
조직몰입도
- 지금 근무하고 있는 직장(일자리)은 다닐만한 좋은 직장이다
- 나는 이 직장(일자리)에 들어온 것을 기쁘게 생각한다.
- 나는 현재 하고(맡고)있는 일을 즐겁게 하고있다.
- 나는 내가 다니고 있는 직장(일자리)을 다른사람들에게 자랑할 수 있다.
- 별 다른일이 없는 한 이 직장(일자리)을 계속 다니고 싶다.
# 라이브러리 로딩
library(dplyr)
library(readstata13)
library(Hmisc)
library(ggplot2)
library(corrplot)
library(tidyr)
library(psych)
library(psy)library(rio)
library(readxl)
library(httr)
# 데이터 셋 가져오기
url ="https://docs.google.com/uc?export=download&id=1O6brl3rVayKaAloz34PUOq6H39XeUXFA"
GET(url, write_disk(tf <- tempfile(fileext = ".xlsx")))
df <- read_excel(tf, 1L) # 1L은 sheet
## 조직몰입도
# 항목 통계량
Q1_df <-df %>%
select(c(conce1,conce2,conce3,conce4,conce5))
head(Q1_df)## conce1 conce2 conce3 conce4 conce5
## 1 4 4 4 4 4
## 2 3 3 3 3 5
## 3 4 4 4 4 4
## 4 3 4 3 4 4
## 5 4 4 4 3 5
## 6 3 3 2 2 4 Q1_df %>%
gather(key = "설문항목", value = "설문결과") %>%
group_by(설문항목) %>%
summarise(평균 = mean(설문결과),
표준편차 = sd(설문결과),
데이터갯수 = n())## # A tibble: 5 x 4
## 설문항목 평균 표준편차 데이터갯수
## <chr> <dbl> <dbl> <int>
## 1 conce1 3.40 0.665 1002
## 2 conce2 3.41 0.653 1002
## 3 conce3 3.28 0.706 1002
## 4 conce4 3.32 0.699 1002
## 5 conce5 3.67 0.667 1002설문 항목과 평균과 표준 편차를 보면 어느 것에서 평균이 차이가 나는지 알수 있다.
# barchart
Q1_df %>%
gather( key = "항목", value ="값") %>%
group_by(항목) %>%
summarise(평균 = mean(값)) %>%
ggplot(aes(항목, 평균, fill = 항목)) +
geom_bar(stat = "identity") |
| 설문항목 |
# 항목별 추세 그래프 그리기
pairs(Q1_df, panel=panel.smooth)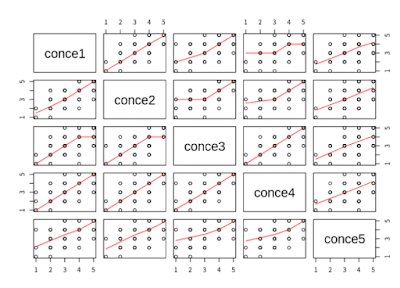 |
| 항목별 추세 그리기 |
# 항목간 상관계수 행렬
cor_df1 <- cor(Q1_df)
cor_df1## conce1 conce2 conce3 conce4 conce5
## conce1 1.0000000 0.7850582 0.7085326 0.7182031 0.5873902
## conce2 0.7850582 1.0000000 0.7459656 0.7439066 0.6214348
## conce3 0.7085326 0.7459656 1.0000000 0.8085646 0.5589926
## conce4 0.7182031 0.7439066 0.8085646 1.0000000 0.5672541
## conce5 0.5873902 0.6214348 0.5589926 0.5672541 1.0000000 # 상관계수 행렬 그래프 그리기
corrplot(cor_df1) |
| 상관계수 행렬 히트 맵 |
상관도 그래프하고, 상관 계수를 보면 설문항별로 차이가 나타나는게 눈으로 보인다. 유독 4번항과 4번항이 관계성이 매우 다르다는 판단이 든다.
# 문항 척도간 크론바 α
alpha(Q1_df)## ## Reliability analysis ## Call: alpha(x = Q1_df) ## ## raw_alpha std.alpha G6(smc) average_r S/N ase mean sd median_r ## 0.92 0.92 0.91 0.68 11 0.0042 3.4 0.59 0.71 ## ## lower alpha upper 95% confidence boundaries ## 0.91 0.92 0.92 ## ## Reliability if an item is dropped: ## raw_alpha std.alpha G6(smc) average_r S/N alpha se var.r med.r ## conce1 0.89 0.89 0.87 0.67 8.3 0.0056 0.0111 0.68 ## conce2 0.89 0.89 0.86 0.66 7.7 0.0059 0.0104 0.65 ## conce3 0.89 0.89 0.87 0.67 8.1 0.0057 0.0082 0.67 ## conce4 0.89 0.89 0.87 0.67 8.0 0.0058 0.0084 0.66 ## conce5 0.92 0.92 0.91 0.75 12.1 0.0040 0.0015 0.74 ## ## Item statistics ## n raw.r std.r r.cor r.drop mean sd ## conce1 1002 0.88 0.88 0.84 0.80 3.4 0.66 ## conce2 1002 0.90 0.90 0.88 0.84 3.4 0.65 ## conce3 1002 0.89 0.88 0.86 0.81 3.3 0.71 ## conce4 1002 0.89 0.89 0.86 0.82 3.3 0.70 ## conce5 1002 0.77 0.77 0.670.653.7 0.67 ## ## Non missing response frequency for each item ## 1 2 3 4 5 miss ## conce1 0 0.06 0.49 0.42 0.03 0 ## conce2 0 0.05 0.51 0.41 0.03 0 ## conce3 0 0.11 0.50 0.35 0.02 0 ## conce4 0 0.10 0.50 0.38 0.03 0 ## conce5 0 0.04 0.29 0.60 0.06 0
# 신뢰도 통계량
cronbach(Q1_df)## $sample.size ## [1] 1002 ## ## $number.of.items ## [1] 5 ## ## $alpha ## [1]0.9155293
아래 전체적인 크론바 알파 내적 일치도는 91.5% 로 어느 정도 높다고 판단 할 수 있으나, 문항 5번 항에서 "별 다른" 이라는 문구가 높은 점수를 유도 한것 처럼 보인다.
5번 항목 빼고 신뢰도 통계량을 보자.
Q1_df1 <-df %>%
select(c(conce1,conce2,conce3,conce4))
# 문항 척도간 크론바 α
alpha(Q1_df1)##
## Reliability analysis
## Call: alpha(x = Q1_df1)
##
## raw_alpha std.alpha G6(smc) average_r S/N ase mean sd median_r
## 0.92 0.92 0.91 0.75 12 0.004 3.4 0.61 0.74
##
## lower alpha upper 95% confidence boundaries
## 0.92 0.92 0.93
##
## Reliability if an item is dropped:
## raw_alpha std.alpha G6(smc) average_r S/N alpha se var.r med.r
## conce1 0.91 0.91 0.87 0.77 9.8 0.0050 0.0014 0.75
## conce2 0.90 0.90 0.86 0.75 8.8 0.0056 0.0030 0.72
## conce3 0.90 0.90 0.86 0.75 9.0 0.0056 0.0011 0.74
## conce4 0.90 0.90 0.86 0.75 8.8 0.0057 0.0015 0.75
##
## Item statistics
## n raw.r std.r r.cor r.drop mean sd
## conce1 1002 0.89 0.89 0.84 0.80 3.4 0.66
## conce2 1002 0.90 0.91 0.87 0.83 3.4 0.65
## conce3 1002 0.91 0.90 0.86 0.83 3.3 0.71
## conce4 1002 0.91 0.91 0.87 0.83 3.3 0.70
##
## Non missing response frequency for each item
## 1 2 3 4 5 miss
## conce1 0 0.06 0.49 0.42 0.03 0
## conce2 0 0.05 0.51 0.41 0.03 0
## conce3 0 0.11 0.50 0.35 0.02 0
## conce4 0 0.10 0.50 0.38 0.03 0 # 신뢰도 통계량
cronbach(Q1_df1)## $sample.size ## [1] 1002 ## ## $number.of.items ## [1] 4 ## ## $alpha ## [1]0.9233794
크게 바뀐것이 없는 것을 보아, 그 문항이 영향도가 크지 않음을 알 수 있다.









댓글 없음:
댓글 쓰기