apply family는 원래 R에서 처음 사용자에게는 넘기 힘든 벽이나, 마찮가지 이다. 하지만, 데이터의 형태를 쉽게 알기 위해 tapply를 만들었는데, 객체지향 프로그램을 잘 다루어 본 사람을 잘 아는데, 그렇지 않은 사람은 이해하기 어려울 수 있다.
참고로 아래 분석에 사용하는 데이터 셋은 아래와 같다.
2.8.1 tapply 함수로 평균 테이블 계산
R 함수에서 가장 중요한 함수 중 하나는 tapply 입니다. 함수명으로 봐서는 중요한 기능을 실행할 것 같지만, 이 함수를 이용해 평균,분산,표본크기, 최솟값과 최대값을 계산 할수 있습니다. 예를 들어 날씨 데이를 이용해 월별 평균 온도를 구한다고 합시다. 온도(temperature)를 반응 변수로, 월(month)을 범주형 설명변수로 선정 합니다.
setwd("~/Dropbox/01.R분석/01.자율교육/2022년 자율교육/3강")
data <- read.table("temperature.txt", header = T)
attach(data)
names(data)## [1] "temperature" "lower" "rain" "month" "yr"평균을 계산하는 함수는 mean입니다. 이를 위해서는 3개의 인자(반응, 변수, 범주형 설명변수, 적용합수 이름)를 갖는 tapply 함수를 호출 합니다.
tapply(temperature, month, mean)## 1 2 3 4 5 6 7 8
## 7.930051 8.671136 11.200508 13.813708 17.880847 20.306151 22.673854 23.104924
## 9 10 11 12
## 19.344211 15.125976 10.720702 8.299830동일한 방법으로 다른 함수를 적용할 수 있습니다. 다음은 var을 사용해 월별 분산을 계산합니다.
tapply(temperature, month, var)## 1 2 3 4 5 6 7 8
## 11.568976 10.743512 10.895535 12.400164 16.517578 14.501635 13.962581 13.538360
## 9 10 11 12
## 9.771223 7.865736 9.510432 11.518656월별 최소값은 min 을 사용합니다.
tapply(temperature, month,min)## 1 2 3 4 5 6 7 8 9 10 11 12
## -6.8 -3.5 1.5 2.8 8.8 11.5 14.3 15.0 7.5 8.3 0.5 -1.8적합한 내장 함수가 없는 경우 해당 함수를 정의해 사용할 수 있습니다. 예를 들어 각 평균의 표준오차를 계산하는 함수를 만들 수 있는데, 작성한 함수는 이름이 없기 때문에 R에서는 무기명 함수라고 합니다.
tapply(temperature, month, function(x) sqrt(var(x)/length(x)))## 1 2 3 4 5 6 7 8
## 0.1401489 0.1414445 0.1358934 0.1476242 0.1673197 0.1596439 0.1539661 0.1516091
## 9 10 11 12
## 0.1309294 0.1155612 0.1291703 0.1398438tapply 함수는 매우 유연합니다. 단순히 1개의 범주형 변수(월)를 list로 대체해 다차원 데이블을 생성 할 수 있습니다. 월평균은 list(yr,month)에 설정한 것과 같이 매년 별도로 계산 합니다. list(yr, month)에서 첫 번째 인자인 연도는 테이블에서 행으로 표시되고, 두 번째 인자인 월은 열로 표시됩니다.
tapply(temperature, list(yr, month),mean)[, 1:6]## 1 2 3 4 5 6
## 1987 3.170968 6.871429 8.132258 14.92667 15.60645 17.73667
## 1988 8.048387 8.248276 9.959375 12.74483 17.31935 18.71667
## 1989 8.841935 9.482143 11.919355 11.09333 20.40323 21.23667
## 1990 9.445161 11.028571 12.487097 13.80000 20.16129 18.51667
## 1991 6.980645 4.817857 12.022581 13.14333 15.58065 16.88000
## 1992 6.964516 8.686207 11.477419 13.35000 20.45806 22.21667
## 1993 10.119355 6.985714 11.209677 14.17000 17.79355 21.10000
## 1994 8.825806 7.217857 11.806452 12.61667 16.23226 20.86000
## 1995 8.309677 10.439286 10.667742 14.79667 18.74063 19.94483
## 1996 7.019355 6.065517 8.487097 13.99667 14.38710 21.93667
## 1997 4.932258 10.178571 13.370968 15.00667 18.17419 19.93000
## 1998 8.759375 11.242857 11.719355 12.55333 19.43226 19.35000
## 1999 9.523333 8.485714 11.790323 14.65000 18.94839 20.00667
## 2000 8.229032 10.324138 11.900000 12.59000 18.22581 20.63333
## 2001 7.067742 9.121429 9.012903 12.65667 18.96452 20.52667
## 2002 9.067742 11.396429 12.319355 15.68667 16.81290 19.67667
## 2003 8.012903 8.171429 13.425806 15.69000 17.36452 22.80000
## 2004 8.261290 8.993103 10.354839 15.17000 17.98065 21.73667
## 2005 9.116129 7.032143 10.787097 13.78333 17.12258 22.00000첨자 [, 1:6]은 실행 결과의 출력을 1~6월까지 제한 한다. 실행 결과 1993년 1월은 이래적으로 따뜻했고, 1987년 1월은 매우 추웠던 것을 계산을 통해 알 수 있습니다. tapply 함수가 원하지 않는 결과를 출력하는 경우가 있습니다. 누락값에 대해 오류 발생 보호 기능을 갖는 함수에 대해 tapply 함수는 연산 결과 대신 NA를 반환 합니다. mean 함수는 데이터에 한개 이상의 누락된 값이 있을 때 기본 반환값이 NA 이므로 이러한 결과가 발생할 가능성이 높습니다. 이러한 문제를 해결 하려면 tapply에 추가 인자를 제공하여, 결측값이 없는 값만을 대상으로 함수 연산을 실행 합니다. 누락 된 값을 제거 하기 위해 다음과 같이 na.rm=TRUE를 사용합니다.
tapply(temperature, yr, mean, na.rm= TRUE)## 1987 1988 1989 1990 1991 1992 1993 1994
## 13.27014 13.79126 15.54986 15.62986 14.11945 14.61612 14.30984 15.12877
## 1995 1996 1997 1998 1999 2000 2001 2002
## 15.81260 13.98082 15.63918 15.02568 15.63736 14.94071 14.90849 15.47589
## 2003 2004 2005
## 16.03260 15.25109 15.06000산술평균은 이상치에 대해 민감한 영향을 받기 때문에 계산 전에 매우 크거나 작은 값을 사전 처리하는 것이 좋습니다. trim 옵션을 사용하면, 중앙값의 평균을 계산하기 전에 정렬된 벡터의 왼쪽과 오른쪽 꼬리에서 생략하기를 원하는 일부 데이터(0~0.5)를 설정 할 수 있습니다.
tapply(temperature, yr, mean, trim =0.2)## 1987 1988 1989 1990 1991 1992 1993 1994
## 13.45068 13.74500 14.99726 15.16301 13.92237 14.32091 14.28000 14.64658
## 1995 1996 1997 1998 1999 2000 2001 2002
## 15.25571 13.75845 15.54064 14.91500 15.44364 14.59318 14.63333 15.33927
## 2003 2004 2005
## 15.70959 15.04136 15.02009예제 1
각 도/연도별(2001~2020) 출생 인원 데이터 셋 가지고 출생 년도별 총 출산 인원 , 시/도별 출산 추세그래프를 그리고 tapply() 함수를 이용하여, 년도별 출산 평균과 합계를 구하십시오.
먼저 데이터 계산에 필요한 패키지를 로딩 합니다.
# 패키지 불러오기
library(stringr)
library(dplyr)##
## 다음의 패키지를 부착합니다: 'dplyr'## The following objects are masked from 'package:stats':
##
## filter, lag## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, union library(tidyr)
library(ggplot2)
library(readxl)국가 통계 포털에서 다운로드 받은 데이터를 로딩 합니다.
born <- read_excel("born.xlsx")국가 통계 포털의 데이터의 기본 구조는 아래와 같이 표1 같이 로 되어 있습니다. 표로 되어 있으면, 엑셀에서 그래프를 그리기 어렵지 않지만, R에서는 표2와 같이 데이터의 구조를 바꾸어 주어야 합니다.
 |
| 대한민국 년도 시도별 출산 |
인구 표1은 R에서 그래프를 그리기 적합한 데이터 구조가 아닙니다. 물론 엑셀에서는 그림을 그리기는 매우 간단 합니다. R은 분석을 위한 용도이기 때문에 아래 표2와 같이 데이터의 구조를 만들어야 합니다.
 |
| 출생아 수 새로로 |
인구데이터 구조 변경은 tidyr 패키지의 gather() 함수를 이용해서 만들어 보겠습니다.
# 데이터셋 세로로 세우기
born <- born %>% gather(년도, 출생아수, -행정구역)
attach(born)
names(born)## [1] "행정구역" "년도" "출생아수"그래프를 그릴때 1e+5와 같은 숫자가 나와서 인구가 몇 명이 출생 하였는지 정확하게 표현 하기 어렵습니다. 따라서 아래와 같이 options() 함수를 이용해서 큰 숫자도 전부 표현이 되어야 하게 하여야 합니다.
# 그래프 그릴때 큰 숫자도 나타나게 처리
options(scipen = 3)ggplot2를 이용해서 시/도별 그래프를 그리겠습니다. ggplot() 함수에서는 x축과 y축을 구분하는데, aes(x축, y축, 옵션)을 넣고 geom_line() 함수만 넣으면 그래프가 그려 집니다.
# 시도별 추세 그래프 보기
born %>%
mutate(년도 = as.integer(년도)) %>%
ggplot(aes(년도, 출생아수, color = "red") ) +
geom_line() +
theme(axis.text.x = element_text(angle = 90))+
facet_wrap(~행정구역, nrow =2) |
| 시도별 추세 그래프 |
그래프도 어떤 각도 어떻게 그리느냐에 따라 해석이 달라 집니다. ggplot의 맨 마지막의
facet_wrap() 함수의 nrow 값을 조정 하면, 시도별 기울기가 바뀝니다.또 다른 각도에서 그래프를 볼수 있습니다. 아래의 그래프는 행정구역이 5개 이상 들어가면, 알아보기가 어렵습니다. 하지만, 출산인구에 대한 기울기는 정확하게 비교 할 수 있습니다.
아래와 같이 tapply() 함수를 이용해서 년도별 합계와 구합니다.
# 년도별 전국 출생아수 평균 구하기
tapply(출생아수, 년도, mean)## 2001 2002 2003 2004 2005 2006 2007 2008
## 34995.88 31056.94 30939.75 29809.88 27419.19 28234.94 31051.38 29118.25
## 2009 2010 2011 2012 2013 2014 2015 2016
## 27803.06 29385.69 29454.06 30218.50 27209.00 27130.69 27232.00 25184.12
## 2017 2018 2019 2020
## 22141.69 20194.94 18678.56 16804.31# 년도별 전국 출생아수 합계 구하기
tapply(출생아수, 년도, sum)## 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 2011
## 559934 496911 495036 476958 438707 451759 496822 465892 444849 470171 471265
## 2012 2013 2014 2015 2016 2017 2018 2019 2020
## 483496 435344 434091 435712 402946 354267 323119 298857 268869그리고 아주 간단하게 tapply() 함수로 합계를 구하것 가지고 년도별 추세 그래프를 간단하게 그리겠습니다.
#년도별 전국 출생아수 합계 그래프
plot(tapply(출생아수, 년도, sum), type="l", col="#DC143C")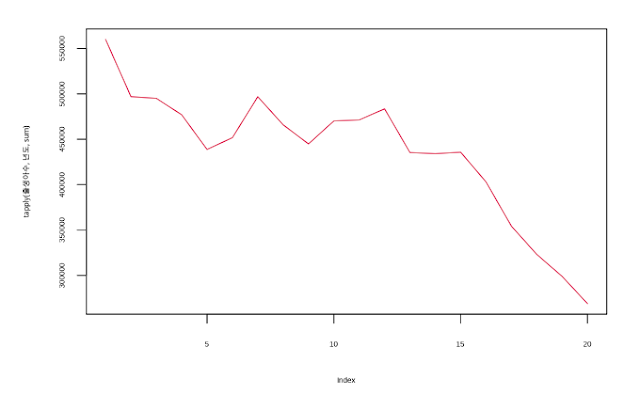 |
| 년도별 출생아 수 |
댓글 없음:
댓글 쓰기